kaggle Playground Series - Season 3, Episode 5
今回はワインの品質レベルの予測。
ワインに含まれる11種類の成分の分布で1~10までの(テストデータは3~8)ランクを予測(多値分類)するというもの。
■キーポイントは3つ
1,2は個人的にトライしてみたい事です。
- optunaを使用したパラメータの最適化
これはわかりやすいコードを書いてくれた人がいたので参考に
させて頂きました。この方は多分日本人。注釈に日本語が使われていたから。
お世話になりました。
optunaは以前トライしたことがあったのですが、その時は労力のわりに効果が少なかったので(個人の力のせい??)その後遠ざかっていました。
改めて見ると対応するアルゴリズムも増えており進化しているようです。
今回使用したLightGBM用のモデルは最適化する特徴量の順番も考慮していました。
とりあえず使ってみたレベルなのでこれ以上のコメントは差し控えます。。
- LightGBMとXGBoostを使用した性能比較やアンサンブルの検討
これまではLightGBM一択だったのですが、XGBoostを使っている人も相当数いるのでこちらにも再トライ。かつ、アンサンブルも合わせて行ったところ順位が上がりました。めでたし、めでたし。
- 特徴量の追加
プレイグラウンドではあまり特徴量を追加する人は少ないように感じているのですが、個人的には毎回トライしています。残念ながらあまり成功したためしがないです。
今回も特徴量間の比率(割り算)を行いましたがノイズが多くなったようでポイントは上がりませんでした。
しかし、科学的に重要なパラメータ(特徴量)をご存知な方が情報をアップしてくれていたのでそちらを使用したところポイントアップ。
やっぱり業務を知っている人はそれだけで大きな強みですね。
今はやりのChatGPTを使った人もいるようでこれもありかもしれません。
■ 結果
316/903位

今回は結構オーバーフィットが起こりやすかったようで、98番も順位が落ちました。
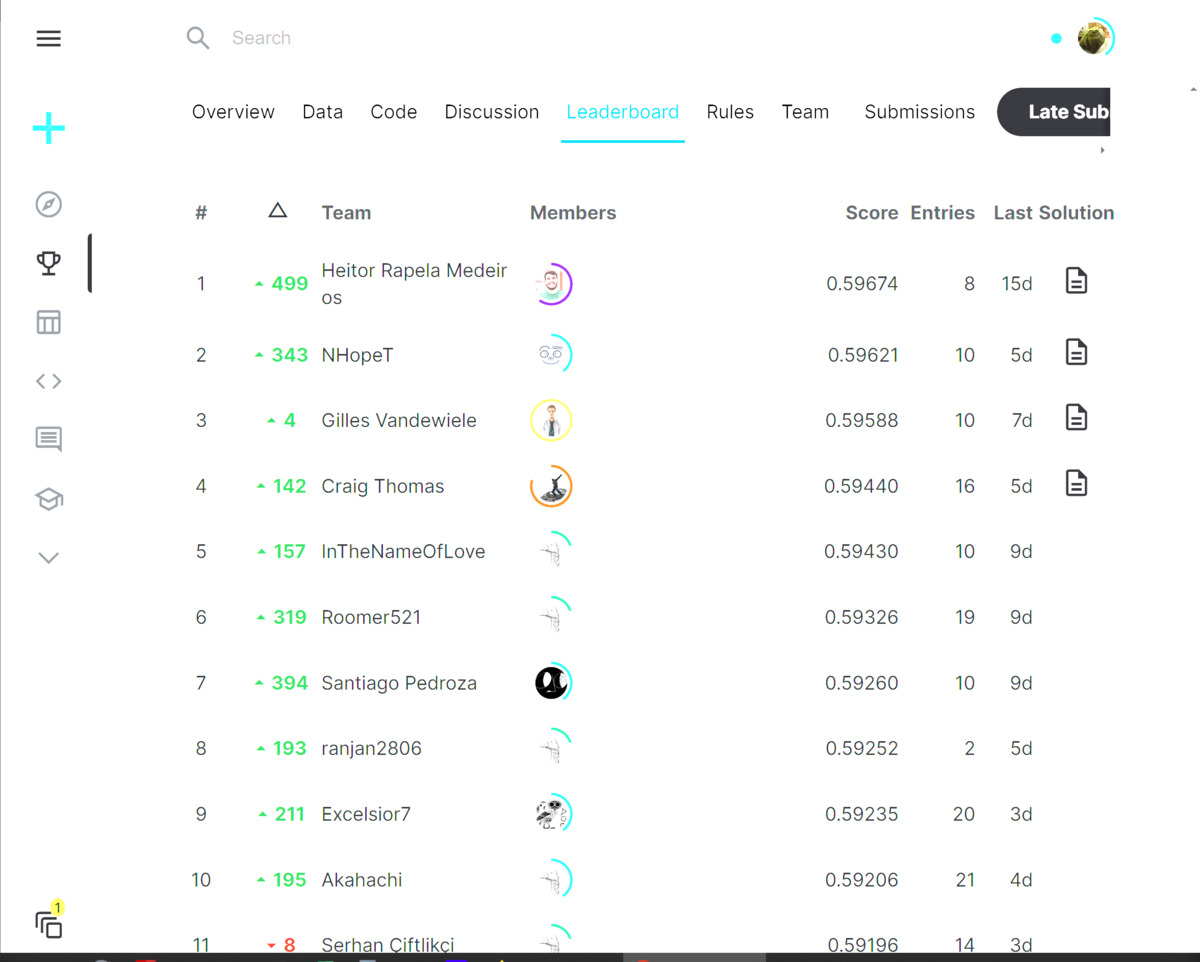
目先のスコアーだけで投稿してもダメだという良い例ですね。
やっぱり奥が深いですね。